These are data science and machine learning projects I've worked on in my spare time. Further description, and links to Jupyter Notebooks, can be found below.
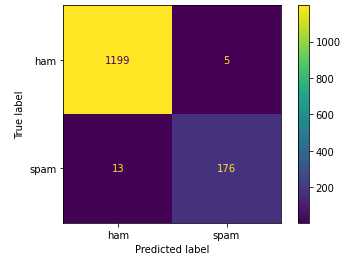
Implementing the Naive Bayes classifier to achieve almost 99% test set accuracy on Kaggle's SMS Spam Collection Dataset. The classifier also achieves high precision (98.8%) and recall (92.7%). The features are based on words used, as well as the presence of money symbols and numbers of various lengths.
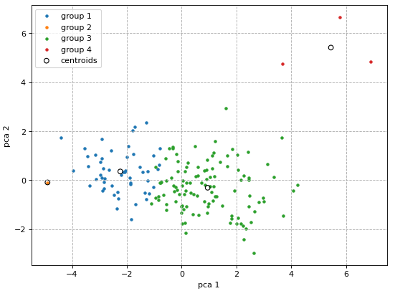
Implementing k-means and the gaussian mixture model to cluster countries based on economic data. The elbow and silhouette methods are used to pick an appropriate number of clusters.
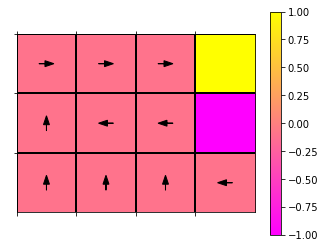
An implementation of value iteration to find the optimal policy for reinforcement learning problems. In the scenario depicted above, the agent is placed 3 cells across and 3 cells down in a 3-by-4 grid. The top-right corner is the goal state, giving a reward of +1. Below that is a fail state, giving a reward of -1. Every other state gives -0.1, incentivising the agent to not dilly-dally. The arrows indicate the direction to move, as proposed by the optimal policy. There's a 75% chance of moving in the intended direction, and a 25% chance of veering left or right. This is why, at grid position (2,3), the optimal decision is to go left, avoiding the possibility of accidentally reaching the fail state.
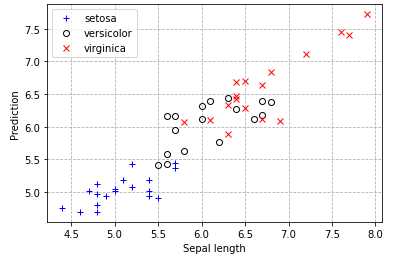
Applying linear models to regression and classification tasks on the iris flower dataset. Also includes my own implementation of gaussian discriminative analysis, which happens to perform worse than logistic regression on this dataset.