I wrote a cute little program to generate poetry in toki pona, the 125-word language that was published by Sonja Lang in 2001.
Here's one of its sick rhymes:
jan sama pi jan,
ike li pona ala,
tawa mi la tan.tenpo ni e kala.
And an attempted translation by u/jedgrei from Reddit. I say attempted because this particular poem doesn't fully make sense.
Because I dislike the enemy of the sibling, now [fish?].
Before I explain how it all works, I should share some relevant facts about toki pona:
Now for an EXPLANATION. The first thing I needed was a bunch of toki pona text (a "corpus"), which I gathered by downloading comments from r/tokipona using a script that I happened to have lying around. Then I created a big ol' Markov chain based on that corpus, using another script that I happened to have lying around.
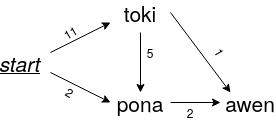
So to generate text with this Markov chain graph thing, you randomly traverse the graph, beginning at the node called start, which represents the start of a sentence. The probability of going from one node to another is weighted by the number of times the words appear next to each other in the corpus. The weight is stored in the edge between the nodes. In this example, the word "toki" appeared at the start of 11 sentences, which means there's a probability of 11/(11+2) that you go from start to toki. Similarly, there's a probability of 2/(11+2) that you go from start to pona. Don't panic!, the probabilities add up to 1.
Here's a path we might follow through the Markov chain, resulting in the sentence "toki pona awen". It depends on which random numbers we pull from our hat, though. We could also end up with "toki awen" or "pona awen".

That's fine for normal text generation, but when you're generating poems, there are extra constraints on the output, such as the number of syllables per line. Or maybe the final word on a line should rhyme with a word from another line.
Here's how the algorithm works with the addition of constraints. Let's say we're generating a line in a poem using the Markov chain from before. We've followed the path start → toki → awen. But we need the last word to rhyme with "sona", which "awen" doesn't.

We retrace our steps back to toki.

Then we try picking pona as the next node, giving: start → toki → pona.

We can stop here, because "pona" happens to rhyme with "sona". We'd also have to backtrack if we exceeded the number of syllables allowed on the line.
That's pretty much how the poem generation works. A concise description would be: weighted random search through a graph, with backtracking.
Maybe, rather than throwing this poem generator on the trash heap of all the useless programs I've written, it'll be the basis for a Twitter or Mastodon bot. Stay tuned (update, May 9th 2021: it's here, after a couple of weeks stuck in Twitter's spam dragnet). In the meantime, here's the code, and below are a few more poems I've generated.
A limerick (rhyming scheme aabba).
a a mama mije ala pali wan,
wan wan seli e pilin pona pi jan.lon li kalama en,
nasin ni li len,
noka nasa mute li pona e pan.
A Shakespearean sonnet (abab cdcd efef gg).
pona taso soweli sina ken,
ante la sijelo pi sitelen,
pona mute li nimi wan wan en,
nimi wan wan wan wan taso mi ken.mani lili tan mi li kon li sin,
lon e kulupu tomo suli kin,
la sina lon pi sona pona kin,
la ona li pona e ma lukin.luka en pilin telo seli sin,
e oko lili pi luka wan wan,
la nanpa lili ni la ona kin,
la lipu mute la mi ali jan.pona ala tan ni li kepeken,
nasin sewi li suli li awen.
And a haiku (abc).
pilin ala ken,
ala mute o lukin,
e kon mun en tan.
Here are all groups of rhyming words, according to my definition of a rhyme. My definition of a rhyme, by the way, is where the last syllables of two words are the same, regardless of whether they're stressed syllables.
There are 61 rhyming words, split between 21 groups. That leaves 64 words without a rhyme buddy :(
It would be a waste not to do anything with the text data from r/tokipona, so here are some quick plots.
Here's a word cloud. The bigger a word is, the more common it is on r/tokipona.

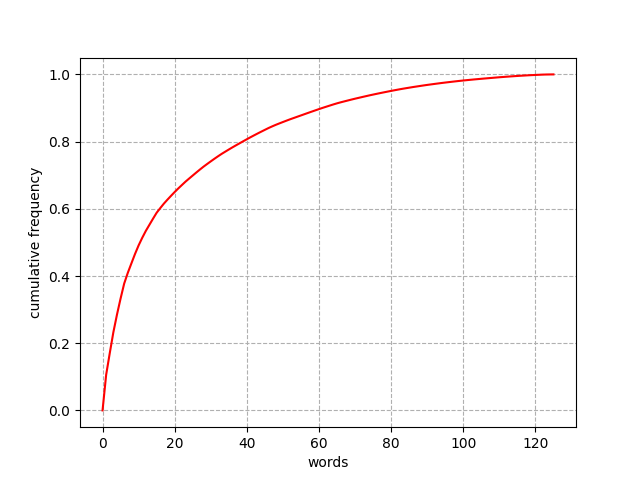
Here's Zipf's law in action, in the form of a cumulative frequency distribution. It basically shows that the top 10 words make up about 50% of word occurrences, while the top 50 words make up almost 90%. This pattern shows up in all human languages, I think.
Aaaand here's a table of all the words, ordered by frequency. BUT WAIT. Something just occurred to me. A lot of people write in English on r/tokipona, so the letter "a" probably appears more popular here than it is in actual toki pona.
| word | count | % | word | count | % | word | count | % |
|---|---|---|---|---|---|---|---|---|
| a | 2331 | 10.59 | ale | 123 | 0.56 | kule | 39 | 0.18 |
| pona | 1419 | 6.45 | jo | 120 | 0.55 | pan | 39 | 0.18 |
| li | 1370 | 6.22 | lipu | 118 | 0.54 | seli | 36 | 0.16 |
| toki | 1154 | 5.24 | moku | 117 | 0.53 | ko | 36 | 0.16 |
| e | 1055 | 4.79 | lawa | 107 | 0.49 | mije | 36 | 0.16 |
| mi | 981 | 4.46 | sama | 102 | 0.46 | mani | 34 | 0.15 |
| ni | 700 | 3.18 | ilo | 94 | 0.43 | palisa | 32 | 0.15 |
| jan | 621 | 2.82 | tomo | 92 | 0.42 | unpa | 32 | 0.15 |
| pi | 616 | 2.80 | suli | 91 | 0.41 | olin | 31 | 0.14 |
| la | 563 | 2.56 | nasa | 89 | 0.40 | awen | 31 | 0.14 |
| ala | 495 | 2.25 | pakala | 84 | 0.38 | akesi | 29 | 0.13 |
| tawa | 455 | 2.07 | pana | 84 | 0.38 | open | 28 | 0.13 |
| sina | 401 | 1.82 | nanpa | 84 | 0.38 | esun | 28 | 0.13 |
| lon | 400 | 1.82 | suno | 84 | 0.38 | kute | 27 | 0.12 |
| mute | 388 | 1.76 | kulupu | 84 | 0.38 | alasa | 26 | 0.12 |
| tenpo | 303 | 1.38 | luka | 83 | 0.38 | pimeja | 25 | 0.11 |
| ona | 293 | 1.33 | pini | 82 | 0.37 | uta | 24 | 0.11 |
| sona | 262 | 1.19 | kalama | 82 | 0.37 | suwi | 23 | 0.10 |
| sitelen | 253 | 1.15 | sewi | 80 | 0.36 | jaki | 23 | 0.10 |
| ken | 246 | 1.12 | soweli | 76 | 0.35 | poki | 21 | 0.10 |
| wan | 235 | 1.07 | sike | 76 | 0.35 | loje | 21 | 0.10 |
| o | 223 | 1.01 | sin | 75 | 0.34 | len | 21 | 0.10 |
| wile | 221 | 1.00 | anu | 71 | 0.32 | selo | 20 | 0.09 |
| ike | 202 | 0.92 | ali | 65 | 0.30 | lete | 20 | 0.09 |
| nimi | 199 | 0.90 | moli | 61 | 0.28 | kipisi | 20 | 0.09 |
| kama | 199 | 0.90 | poka | 60 | 0.27 | jelo | 20 | 0.09 |
| pilin | 194 | 0.88 | wawa | 60 | 0.27 | oko | 18 | 0.08 |
| ma | 188 | 0.85 | linja | 58 | 0.26 | waso | 18 | 0.08 |
| tan | 175 | 0.80 | kiwen | 55 | 0.25 | sinpin | 17 | 0.08 |
| nasin | 171 | 0.78 | insa | 55 | 0.25 | monsi | 16 | 0.07 |
| tu | 168 | 0.76 | kin | 54 | 0.25 | laso | 16 | 0.07 |
| lili | 163 | 0.74 | telo | 54 | 0.25 | anpa | 15 | 0.07 |
| kepeken | 157 | 0.71 | mama | 51 | 0.23 | nena | 14 | 0.06 |
| taso | 145 | 0.66 | sijelo | 50 | 0.23 | pipi | 14 | 0.06 |
| musi | 143 | 0.65 | kili | 49 | 0.22 | noka | 12 | 0.05 |
| ante | 141 | 0.64 | mu | 48 | 0.22 | lape | 11 | 0.05 |
| ijo | 135 | 0.61 | meli | 47 | 0.21 | kala | 11 | 0.05 |
| pali | 133 | 0.60 | utala | 47 | 0.21 | walo | 11 | 0.05 |
| en | 133 | 0.60 | mun | 45 | 0.20 | namako | 7 | 0.03 |
| pu | 131 | 0.60 | weka | 44 | 0.20 | supa | 4 | 0.02 |
| seme | 130 | 0.59 | kon | 43 | 0.20 | lupa | 3 | 0.01 |
| lukin | 125 | 0.57 | kasi | 40 | 0.18 |
I'd be happy to hear from you at galligankevinp@gmail.com.