Tags: probability
<< previousnext >>A hash function takes arbitrarily complex input - a word, a website, an image, a human being - and maps it to a single number. This is useful for various computer science stuffs, such as data storage and cryptography.
For example, let's say you want to store a book in one of boxes. If you put the book in a random box, it's quite likely that you'll forget which box you picked, especially as gets bigger. What you can do instead is apply a hash function to the title of the book (probably The Notebook, knowing you), which will spit out a number, . You then put your book in the -th box1. When you want to retrieve The Notebook again, you recompute the hash function and it tells you to look in the -th box, without you needing to remember where you stored anything! You won't lose a book from your Nicholas Sparks collection ever again.
We won't get into the specifics of what a hash function looks like. This post is instead concerned with hash collisions, which happen when your hash function assigns the same value to two different items. This might be a Bad Thing. Our hash function wouldn't be very useful, for instance, if it told us to put all our books in the 1st box, because we'd have to spend a lot of time rooting around in that box to find a specific book2. For this reason, a good hash function should have evenly distributed outputs. But even then, it's only a matter of time before a hash collision occurs as we add more and more books to our collection. By the time we reach books, there won't enough boxes to store the books individually and there will definitely be at least 1 hash collision.
Given boxes and books, how do you figure out the probability of a hash collision? Hash collisions can be a Bad Thing, but rather than trying to eliminate them entirely (an impossible task), you might instead buy enough boxes that the probability of a hash collision is relatively low.
Jeff Preshing wrote a neat article on how to calculate hash collision probabilities, but there are some gaps in his explanation. This is my attempt to fill those gaps. To follow along you'll need a basic understanding of probability and an iron will.
Consider the following problem statements.
When you compute the hash values of 500 different book titles from your magnificent book collection, and put each book into the corresponding box in a row of 100,000 boxes (yes, it's a lot of boxes), what's the probability that at least 2 books will be in the same box? (~71.3%).
When you put 50 balls into 100 buckets at random, what's the probability that at least 2 balls will end up in the same bucket? (~99.99997%).
When there are 30 people in a room, what's the probability that at least 2 of them will share a birthday? (~70.6%).
These are all versions of the notorious birthday problem. It's notorious because it's not immediately intuitive why the probabilities are so high. The key is that even though there are only 50 balls in problem #2, there are 1225 pairs of balls, and only one of those pairs needs to be in the same bucket. Problems #1 and #3 have the exact same structure. In problem #1, you can think of the books as balls and the boxes as buckets, and in problem #3, the people are balls and the days of the year are buckets.
The problem of calculating hash collision probabilities IS the birthday problem. Let's look at how to solve the birthday problem.
To calculate the exact probability of two or more people sharing a birthday in a room of people, it's easiest to first figure out the probability of none of them sharing a birthday. In this case, , since instead of boxes there are 365 possible birthdays.
The first person to enter the room has probability
of not sharing a birthday with anyone, because duh, there's nobody else in the room!
The probability that the first and second person to enter the room don't share a birthday is
because there are out of days free for the second person.
The probability that the first, second and third person don't share a birthday is
This continues until everyone is in the room and we get that the probability of no shared birthday is
The probability of at least 1 shared birthday, i.e. of a hash collision, is then the complement of there being no shared birthdays:
And... that's it. That's the EXACT probability of a hash collision for items and possible hash function outputs! All right, pack your bags and go home. Nothing more to see here.
But actually, this formula gets clunky as and get big. Imagine you have 1 billion books. Do you really want to multiply 1 billion numbers together? I bet not. Even a computer will take a long time to multiply 1 billion numbers. For this reason, approximations of the formula are often used, as we will see next.
A first approximation of the hash collision probability can be derived by rewriting equation (1) so that the terms in the product are written as complements:
Now, here comes a trick. It's a fact that as gets small (see Appendix A for a proof, which was omitted from Preshing's article). You might notice that we rewrote the terms in the product to match the form , where for varying . Since is presumably much larger than and is therefore small, we can use our cute little approximation to get
The last equality comes from the fact that .
This approximation reduces the complexity of computing the probability, from to . Or, phrased in non-computer-science terms: instead of doing around math operations, we only have to do a small fixed number of them! What's more, the approximation becomes more and more accurate as we increase .
It's possible to simplify this equation even further, using the exact same trick as before! Note that the final line of equation (2) is in the form , where . We've already seen that when is small, and so the hash collision probability can be further approximated by:
...which is funny, because is the number of pairs of items, which I brought up earlier to provide an intuition for the birthday problem!
The final approximation suggested by Preshing is that starts to look an awful lot like as gets bigger (see Appendix A), so the formula can be written simply as
And there you have it. 4 different methods of calculating the hash collision probability, with varying levels of accuracy.
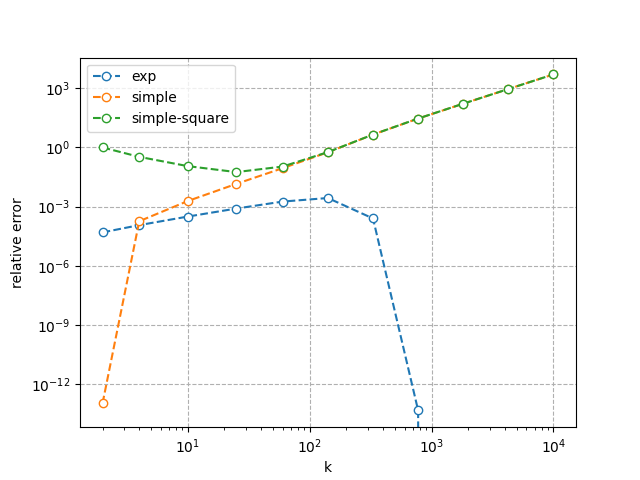
How do the approximations fare? Here's a plot of their relative error compared to the exact birthday calculation, for .
The relative error between two quantities and is , and the smaller it is, the better. If , the approximation is within an order of magnitude of the true value. We see that the exponential approximation gradually gets better as gets smaller. But also, once or thereabouts, the relative error drops like a stone. The simpler approximations are kinda reasonable for , but after that point they go bonkers.
HERE'S A SAMPLE DATAPOINT. At , the real collision probability is about . The exponential approximation is about , and if you squint a little, you could mistake them for the same answer. The simplified approximation is about , which is, you know, still quite good. And the simplest approximation is , which is less quite good.
I was going to dig into the error behaviour of the approximations, but I think I'll get a sandwich instead. Something something exercise for the reader.
We have seen how to calculate the probability of a hash collision, as well as 3 different ways to approximate this probability. The exponential approximation appears to be robust. The other two are convenient for back of the envelope calculations, but may lose their nerve as you add more books to your collection. Finally, if you want to play around with the birthday problem parameters, I've posted a hash collision calculator on the site.
How do we prove that the approximations we've used are "good" in some sense? Or more specifically, that:
This might seem obvious (in the case of #2, just set x=0 and they're the same!), but I was wondering how you would go about it with slightly more rigour.
One approach is based on ratios. Use to denote the function being approximated, and to denote the approximation, and show that . Since implies , this means that and converge in some sense.
I've had a shot at the proofs, below. I'm not a mathematician, so don't take them seriously, although the sages of r/learnmath did review them for me.
For #1, the proof is:
For #2, we use the Taylor series expansion of ,
Applying this expansion to the ratio, we get
If , then you take the book at position . In other words, when you're counting up to the -th box, loop back to the 1st one if you ever exceed . ↩
Here's another motivation for avoiding hash collisions. Let's say you're designing a customer database for a particularly privacy-conscious fish monger. Rather than storing a customer's name in the database, which would be a horrific breach of privacy, you can instead apply a hash function to their name and store the resulting hash value. A hash collision occurs when two customers are assigned the same hash value by the hash function, which could result in the customers' fish orders getting mixed up. How embarrassing! What this means is that you need the range of the hash function (the number of buckets, ), to be large enough that a hash collision is ASTRONOMICALLY UNLIKELY. ↩
I'd be happy to hear from you at galligankevinp@gmail.com.